Views: 0
题目
做法
下载文件,拖进Exeinfo PE
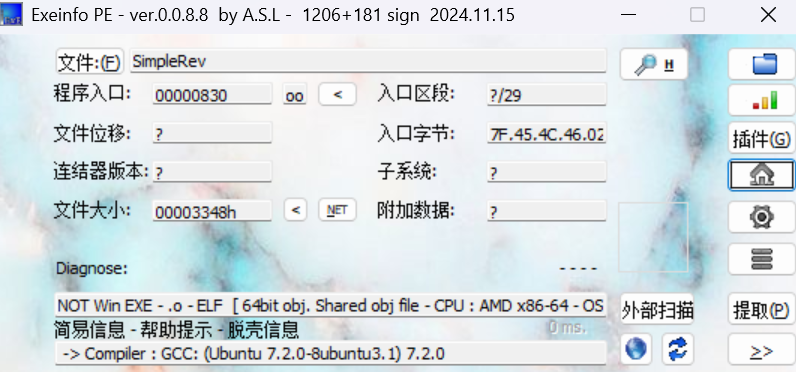
64位,无壳
扔进IDA(64位),找到main,F5反编译
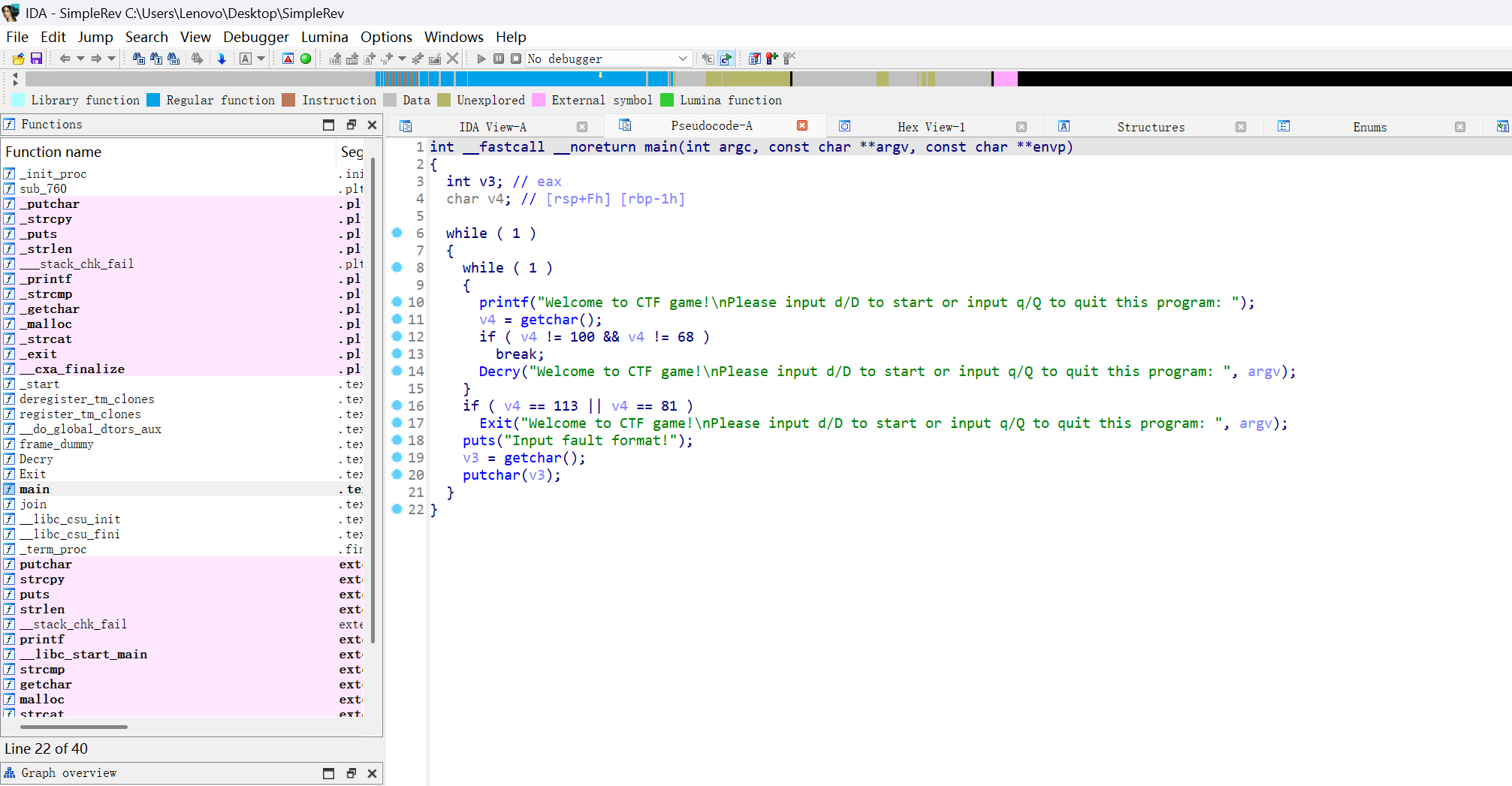
有数字,我们按r转换为字符看看
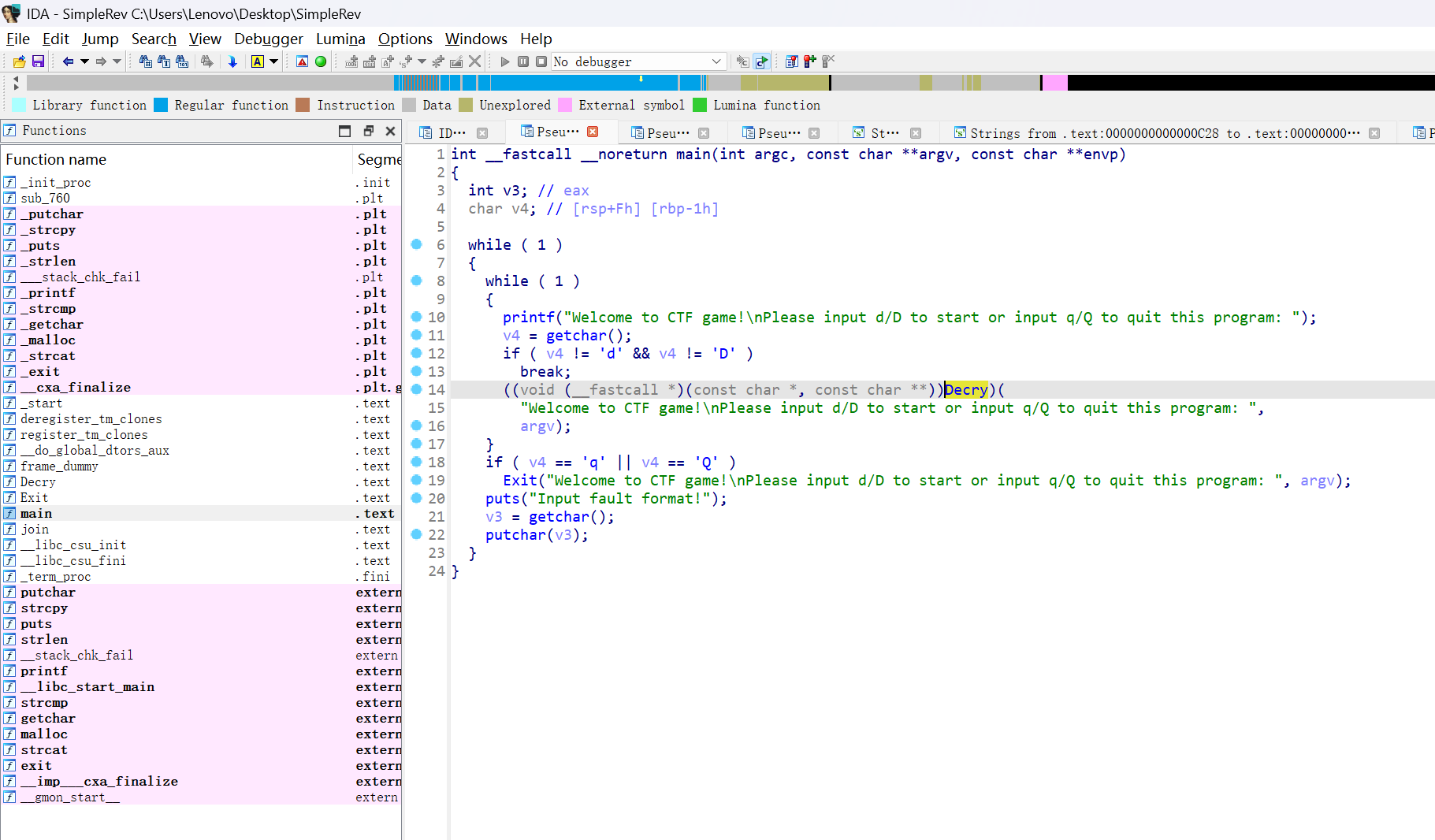
若v4=d/D,我们就可以进入Decry函数
若v4=q/Q,我们就退出
输入除去这几个的其他字母,结果均是break
putchar函数呢,则是将用户输入的字符回显到屏幕,没啥作用
我们点进去Decry函数看看
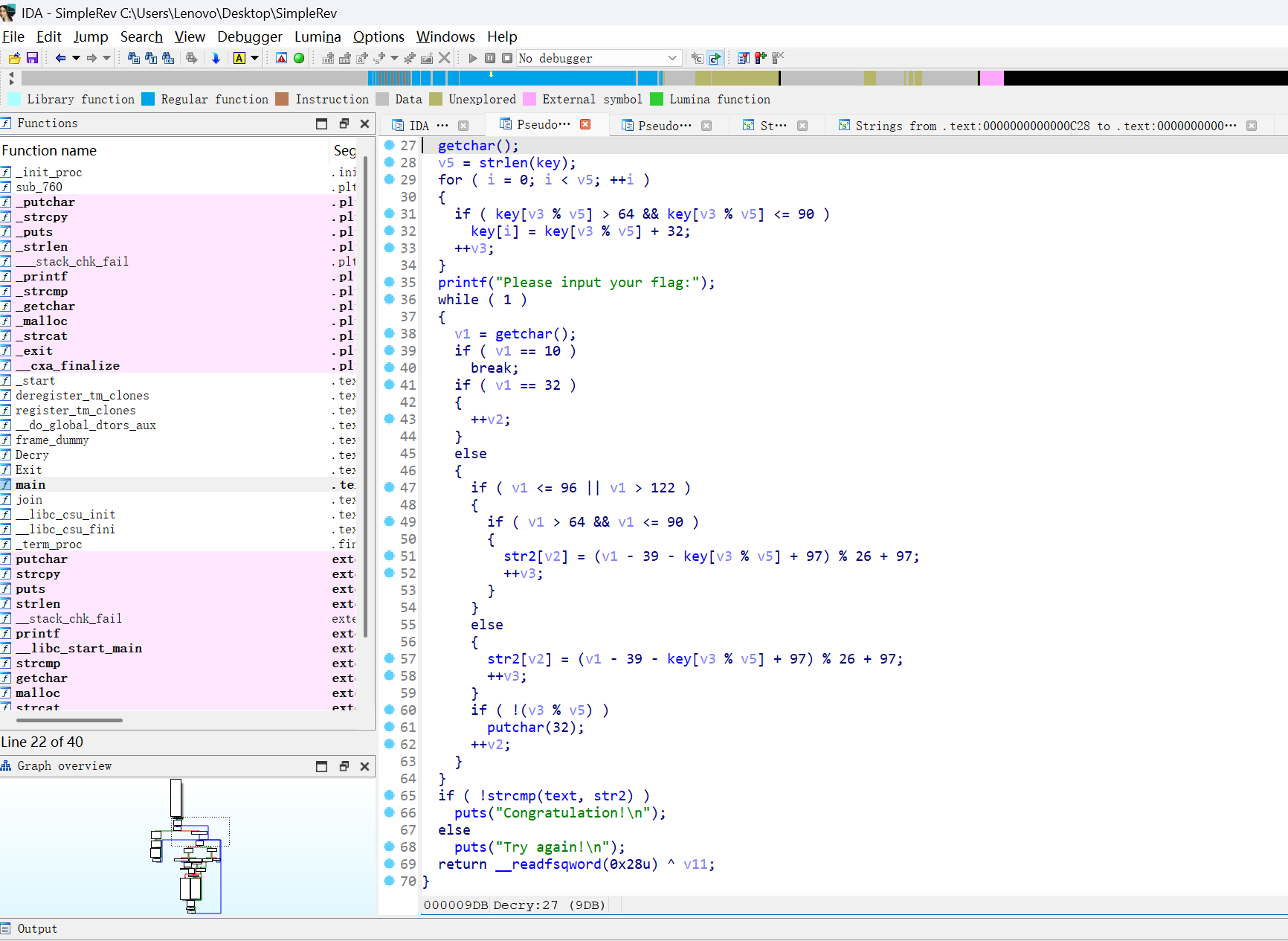
找到真面目了
if ( !strcmp(text, str2) )
puts("Congratulation!\n");看到这里的congratulation,结合上面的Please input your flag,我们就知道该从这里往上分析了
congratulation的条件是:让text等于str2
然后我们自上而下进行分析(以下只节选重要部分进行分析)
一、变量初始化与内存布局
v11 = __readfsqword(0x28u);
*(_QWORD *)src = 0x534C43444ELL;
v9[0] = 0x776F646168LL;- 栈保护机制
v11 = __readfsqword(0x28u):读取线程局部存储(TLS)中的金丝雀值(canary),用于检测栈溢出攻击。
- 字符串初始化(小端序存储)
src被初始化为0x534C43444ELL(十进制 357761762382):- 按字节拆分:
0x53('S') 0x4C('L') 0x43('C') 0x44('D') 0x4E('N') - 小端序存储后内存布局为:
4E 44 43 4C 53→ 字符串为"NDCLS"
- 按字节拆分:
v9[0]被初始化为0x776F646168LL:- 按字节拆分:
0x77('w') 0x6F('o') 0x64('d') 0x61('a') 0x68('h') - 小端序存储后内存布局为:
68 61 64 6F 77→ 字符串为"hadow"
- 按字节拆分:
二、密钥与目标字符串生成
text = (char *)join(key3, v9);
strcpy(key, key1);
strcat(key, src);-
生成目标字符串
textjoin(key3, v9)将key3和"hadow"连接,结果存储在text中。 key1和key3都是一样,双击进去即可看到其值
-
生成加密密钥
keykey初始化为key1,再追加"NDCLS"。
-
密钥处理
- 将
key中的所有大写字母转换为小写:for (i = 0; i < v5; ++i) { if (key[v3 % v5] > 64 && key[v3 % v5] <= 90) key[i] = key[v3 % v5] + 32; // 大写转小写 ++v3; }
- 将


-
条件判断:
key[v3 % v5] > 64 && key[v3 % v5] <= 90
检查字符是否为大写字母(ASCII 范围 65-90) -
转换操作:
key[i] = key[v3 % v5] + 32
将大写字母转换为小写(ASCII 中,小写字母比大写字母大 32)
当 v3 从 0 递增到 9 时,v3 % v5 的结果为 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
因此,v3 % v5 会循环遍历 key 的每个字符(0 到 v5-1)
key[i]是数组,索引从0开始,因此,上面结果为0的key[0]即是key的第一个元素
%:百分号,表示求余运算,如5%4=1
注:
可能会有觉得上面的再扩展的话(比如v3=10,v5=10,v3%v5时结果为key[0]与v3=0,v5=10时也是等于key[0]这般重复的情况)会有俩个key[0],key[1]等 但是这种情况是不存在的,这种情况已经跳出了v5的范围,想法也是错误的 因为程序规定为< v5,这个想法已经不属于这个范畴了 v3不可能取值到10,若其取值到10,则与< v5冲突了 若v3取值到10,则说明v5有11个元素,但是v5只有10个元素
正确的:(假设v5为14)(与上面作出区分,便于观察) (一般规律,下次碰到一样的就不用继续算了)
| 迭代 | i |
v3 |
v3 % 14 |
key[v3 % 14] |
操作 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | ‘a’ (97) | 不转换 |
| 2 | 1 | 1 | 1 | ‘b’ (98) | 不转换 |
| … | … | … | … | … | … |
| 14 | 13 | 13 | 13 | ‘n’ (110) | 不转换 |
上面说的有俩个key[0],key[1]这般重复的情况还有一种为v5被误设为较小值 这种情况的话一般会提前结束,若还是此题目的逻辑的话(< v5)则程序只会处理key的前v5个字符,而不会处理v5及其后字符
因此,无论何种情况,均不会有俩个key[0],key[1]这般重复的情况
补充: 在 C 语言中,字符本质上是以ASCII 码(或其他字符编码)的形式存储的。当你对字符进行数学运算时,C 语言会自动将字符转换为对应的整数值(即 ASCII 码值)
char c = 'A';
int num = c + 32; // 'A'的ASCII码(65) + 32 = 97
printf("%c\n", num); // 输出: 'a' (ASCII码97对应的字符)三、用户输入处理与加密过程
printf("Please input your flag:");
while (1) {
v1 = getchar();
if (v1 == 10) // 换行符
break;
if (v1 == 32) // 空格
{
++v2;
} //在此之下就是else开始加密,因此为过滤掉这俩
// 加密逻辑
if ( v1 <= 96 || v1 > 122 ) //非小写字母ascll码范畴
{
if ( v1 > 64 && v1 <= 90 ) //如果是大写字母
{
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97;
//任何整数除以 26 的余数必定在 0-25 之间
//最后+97是把ascll码范围回到小写字母的ascll码范围(即(0~25)+97对应)
++v3;
}
}
else //小写字母
{
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97; //同上处理方式
++v3;
}
if ( !(v3 % v5) ) //如果v3是v5的整数倍(即处理完一轮密钥)
//本来 % 是取余运算,算出结果是余数,这里前面加了!即为没有余数,则只能是整数
putchar(32); //输出一个空格
++v2;- 输入过滤
- 忽略换行符(
\n)和空格。
- 忽略换行符(
-
加密算法
-
对非小写字母进行处理:
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97;
-
- 密钥循环使用
- 密钥
key循环使用(通过v3 % v5实现) - 每处理完一轮密钥(即
v3是密钥长度的整数倍),输出一个空格。
- 密钥
四、验证与结果
if (!strcmp(text, str2))
puts("Congratulation!\n");
else
puts("Try again!\n");- 将用户输入加密后的结果(
str2)与目标字符串(text)比较。 - 若匹配,输出
"Congratulation!",否则输出"Try again!"。
五、解密方法
要逆向推导出原始 flag,需根据加密公式编写解密函数:
key = "adsfkndcls"
text = "killshadow"
v3 = 0
for i in range(10): #10代表我们要解密的字符数
for j in range(128):
# 跳过非字母字符
if j < ord('A') or (j > ord('Z') and j < ord('a')) or j > ord('z'):
continue
# 这里的ord是让字符变成ascll码,这里说的是范围规定在英文大小写字母范围内
# 核心解密公式
if (j - 39 - ord(key[v3 % 10]) + 97) % 26 + 97 == ord(text[i]):
print(chr(j), end='')
v3 += 1
break得出flag,返回题目提交
补充
1、大小端序
eg.0x123456 0x12通常是高字节,然后0x56是低字节(一般都是这么个顺序,前高后低)
大端序:高字节存放在低地址,低字节存放在高地址 小端序:高字节存放在高地址,低字节存放在低地址
二者正好相反
读取顺序一般是从低地址开始读起
eg.0x123456 大端序:从0x12开始向右读 小端序:从0x56开始向左读
2、如何判断题目给的到底是大端序还是小端序
(1)查看方法
大小端序可以使用软件查看,比如:Detect It Easy
可以看到字节序(小LE)/(大BE)
(2)代码中隐含的端序:
当代码使用整数直接初始化字符串时(如*(QWORD*)src = ...),默认依赖于编译环境的端序(如 x86 为小端序)。
(3)显式判断端序:
int isLittleEndian() {
int num = 1;
return (*(char*)&num == 1); // 1为小端序,0为大端序
}(4)常见应用场景:
小端序:x86/AMD64 架构(Windows/Linux)、ARM 架构(移动端)。 大端序:网络协议(如 IP 地址)、Java 字节码、部分嵌入式系统(如 PowerPC)。 混合场景:文件格式(如 BMP 为小端序,PNG 为大端序)。
更新
于2025.06.17